Can you remember the last time you wanted to find information online but simply couldn’t, no matter how hard you tried? If you started using the internet sometime after Google’s 1998 debut, the answer is feasibly “never.” If it exists on the web, Google’s search engine makes it a snap to find even the most obscure site through the magic of website indexation.
This convenience comes courtesy of Google’s Search index, a vast database of web pages designed to match user queries with pertinent results. Translation? If you want people to be able to find a website quickly, you need Google to index it.
What Exactly Is Website Indexation?
The Google Search index is akin to a virtual filing cabinet. Instead of holding hundreds of papers, though, it holds hundreds of billions of web pages gathered from the farthest reaches of the internet.
Google’s search algorithms analyze this index to provide users with relevant results to their queries. This is why website indexation—also called search engine indexing—is so important. A site needs to be indexed before it can show up in Google’s search results.
To get a site indexed, you’ll need to ensure Google can browse it with its web crawlers, collectively referred to as Googlebot. When Googlebot looks at a website, it follows links and visits different pages similar to the way a human would.
Each page’s information is then sent back to Google’s servers, where it’s organized in the index based on content, freshness, page speed, trustworthiness and a host of other factors. When a user makes a query, Google searches its index to generate the most relevant results possible. The more relevant a page is to a given query, the higher it ranks in search results.
See If a Site Is Already Indexed
Before you get into the weeds of website indexing, you can use Google’s free URL Inspection tool to see if a site or any of its pages have been indexed. Besides telling you if a site is indexed or not, this tool will also display any indexing issues.
Note that you’ll need to use Google Search Console to access the URL Inspection tool, which requires website verification.
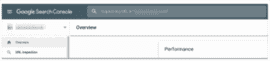
If you can’t (or don’t want to) go through the verification process, simply go to Google and in the search bar, enter:
site:examplesitename.com
To check for a specific page, enter:
site:examplesitename.com/examplepagename
If no results appear, the site or page hasn’t been indexed at all. Keep in mind that for a new site, it may take a few days for Google to find, crawl and index it.
If there are fewer results than there are site pages, Google has indexed some of the site’s pages.
If there’s a result for every page of the site, Google has successfully crawled and indexed the site in its entirety.
Find and Fix Website Indexation Issues
Just because Google crawls a page doesn’t mean it will index it. Why? Google may neglect to index a page (or even an entire site) if the site or page:
- has too much duplicate content;
- has signaled to Google it shouldn’t be indexed via the noindex directive;
- has signaled to Google it shouldn’t be indexed via the rel=sponsored, rel=ugc or rel=nofollow attributes;
- doesn’t have a sitemap;
- takes too long to load;
- contains JavaScript web applications Google can’t easily access;
- has WordPress privacy settings that disallow indexing; or
- has crawl errors.
If a site has one or more of those issues, you’re not out of luck. Each one can be addressed and remedied, typically in just a few steps.
- Remedy duplicate content with the canonical tag.
- Make sure the page has neither a noindex meta tag in its HTML code, nor a noindex HTTP response header.
- Make sure internal inbound links aren’t unnecessarily using the rel=sponsored, rel=ugc or rel=nofollow attribute values.
- Create and submit a sitemap to help Google crawl the site’s pages more efficiently.
- Improve page speed with code validation, WordPress plugins, image optimization and other simple tactics.
- Ensure Google can easily index any JavaScript web apps.
- Verify the site’s WordPress privacy settings are set to allow indexing.
- Use Google’s Index Coverage report to identify any crawl errors.
The one exception is if a site has been removed from the index for not adhering to the webmaster quality guidelines or publishing illegal content.
In that scenario, the only solution is to bring the site up to Google’s standards and submit a reconsideration request.
Ask Google to Index a Site
You’ve checked whether Google has indexed the site, and you’ve addressed any indexing obstacles. Now, you can send Google a direct indexing request to speed things along even further.
To do this for individual URLs, access Google Search Console and use the URL Inspection tool. If you get the “URL is not on Google” message, select “request indexing.”
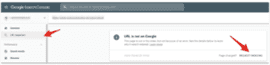
After running a live test to identify any unaddressed issues, Google will queue the page for indexing.
If you want to request indexing for several URLs at once, a more efficient method is to submit or resubmit a sitemap. If you’ve never sent Google a sitemap before, you’ll need to build one.
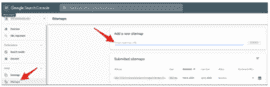
If you have sent Google a sitemap before, resubmitting a new version via the sitemaps report signals to Google that you want a variety of URLs to be indexed. Be sure the sitemap you’re sending has indeed been updated, though. Resubmitting an unchanged sitemap has no benefit, and is just a waste of time.
Trim the Fat, Season the Meat
A less direct way to facilitate website indexing is to trim away any extraneous and outdated content, while ensuring the content that make the cut is as high-quality as possible.
To keep things straightforward, start by paring nonessential pages. You don’t want to spend time reworking a page’s content only to realize it will all be nixed anyway.
Nonessential pages are:
- outdated (e.g., pages for products no longer being sold);
- superfluous (e.g., multiple pages readily condensed into one);
- irrelevant (e.g., pages addressing topics completely unrelated to the site’s purpose); or
- any combination of the three.
By pruning such pages, you’ll be able to guide Googlebot to the site’s high-value pages, increasing their chances of ranking. This strategy can be summed up as maximizing crawl budget, which is the number of pages on your site Google will crawl per day.
Having too many low-value pages can have a negative effect on a site’s crawling and indexing.
Once you’ve removed any nonessential pages and freed up some of the site’s crawl budget, shift your focus to improving remaining content.
Fix Spelling and Grammatical Errors
Google might not specifically penalize poor spelling and grammar, but such mistakes lead to a substandard user experience, which may lead to lower rankings.
Avoid Keyword Stuffing
It creates a negative user experience, and Google expressly recommends that sites stay away from irrelevant or overused keywords.
Keep Things Organized
Use headings and line breaks to divide content into easily readable chunks, and always clearly differentiate between topics.
Make Sure Each Page Offers Value
Google doesn’t give priority to pages with the most keywords or the flashiest graphics. It seeks out reputable sources that provide valuable information to users.
Leverage Internal Links
Links are the bread and butter of website indexation. Without links, Google wouldn’t know how to access certain pages, which pages are the most important and which are being visited the most.
Well-placed internal links give Googlebot clear paths to follow throughout the site, making it easier to index each page. The catch is those links have to be relevant and high-quality.
For instance, if a site has a blog post mentioning content creation services, it shouldn’t link to the site’s landing page about paid media services. Neither page will benefit, and neither will the reader.
To find out which keywords a page is already ranking for (and thus, which keywords can be used to create high-quality internal links), you can use tools like Ahrefs’s Organic Keywords metric.
Once you’ve identified the keyword(s) you want to target, go through the site’s pages and add internal links where appropriate. Throughout the process, remember to use a light touch and keep the links relevant.
Clean Up Inbound Links
Even links that weren’t intentionally created to manipulate search result rankings can be considered low-quality. For example, if a site is linked to a wide variety of low-quality sites, Google will view those links as low-quality by association.
It’s possible to avoid subpar inbound links with a two-pronged approach: Cultivate high-quality links from reputable sources, and reduce the number of low-quality links or links from disreputable sources.
To build top-notch inbound links, you can:
- republish the site’s content on relevant third-party sites, a strategy known as content syndication (remember to use the rel=canonical tag);
- publish well-written guest posts on respected third-party sites;
- create original, easily-shareable content such as videos, infographics and images; and
- regularly post creative and engaging social media content.
Remember to take unlinked mentions into consideration, too. If a site is mentioned on another (trustworthy) site but isn’t linked, that mention has the potential to be converted into a valuable inbound link.
Next, you’ll need to tackle any undesirable inbound links and try to eliminate as many as possible. You can use tools such as Ahrefs’s Backlink Checker or SEMrush’s Backlink Checker to see all the inbound links and identify any you don’t want.
Once you’ve uncovered any backlinks you’d rather not have pointing to the site, try contacting the webmasters of the originating sites. If the webmasters are unresponsive or unwilling to remove the links, or if there are simply too many links to address individually, you can manually disavow them. By disavowing backlinks, you’re telling Google you don’t want a site to be affiliated with them.
Resolve Orphan Pages
If a page contains no internal links, it’s called an orphan page (or ghost page, depending on who you ask). Users have no way of accessing such pages unless they follow links from external sites (if there are any), but search engines can find them if they’ve been submitted for website indexation or included in a sitemap.
While Google doesn’t specifically “punish” websites for having orphan pages, they can easily cause SEO snags. A large number of low-value orphan pages can waste crawl budget, and may signal to Google a site is intentionally hiding pages stuffed with keywords or otherwise designed to manipulate search result rankings.
Orphan pages also represent a missed opportunity to lead Googlebot to the pages you dowant indexed. This is especially true for orphan pages containing duplicate content. Instead of sitting idle, they could be pointing crawlers (and therefore passing link equity) to higher-importance pages via the rel=canonical tag.
So how do you find a site’s orphan pages? You can parse through the sitemap or analyze the site’s web server log files. But you can do it with a lot less work, in a lot less time.
One of the easiest ways is to use the paid version of Screaming Frog’s SEO Spider to find orphan pages.
To resolve the orphan pages you find, you have a few options:
- If you want visitors to find the page in search results, add an internal link to it.
- If you want the page to act as a non-canonical duplicate page pointing crawlers to a canonical page, add the rel=canonical tag.
- If it’s neither a duplicate page nor a page you want visitors to find, archive it.
- If there’s a valid reason for the page to be unlinked (e.g., an email campaign-specific landing page), simply leave it as is—a small number of orphan pages is unlikely to have a significant impact on crawl budget.
Publish More Blog Posts
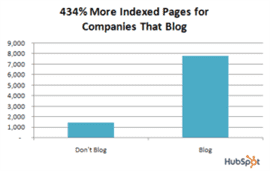
In addition to attracting new visitors, and compared to their non-blogging counterparts, companies that blog have:
- a whopping 434 percent more indexed pages;
- 97 percent more inbound links; and
- 55 percent more site visitors.
For indexed pages, that 434 percent increase translates to a total of nearly 8,000 indexed pages for companies that blog, versus about 1,500 for those that don’t.
That’s largely because Googlebot crawls new web pages more quickly than it crawls old or static ones. The lesson is clear: With a steady stream of new blog posts, sites can get many more pages indexed by Google than they would otherwise.
Get Indexed, Get Noticed, Get Visitors
For any site you want visitors to be able to find, website indexation is the name of the game. Once a high-value site is fully crawled and indexed, its chances of being found in Google’s search results increase dramatically.
With a comprehensive set of simple tactics, search engine indexing stops being a mystery and becomes an attainable goal you can start working toward today.
Image Credits
HubSpot / September 2017





