Semrush’s Site Audit tool is capable of uncovering a wide array of issues. These issues can be grouped into three categories:
- errors;
- warnings; and
- notices.
To make the most of Site Audit, you should get familiar with the differences between the three:
- Errors include technical issues that are of the highest severity on the site. These issues should be fixed and placed at the highest priority in SEO audit recommendations.
- Warnings include issues that are of a medium severity on the site. These issues should be fixed and next in line for priority purposes.
- Notices are not considered major issues, but they can present issues if they are not managed appropriately. These issues should only be addressed after all a site’s errors and notices have been resolved.
Let’s take a look at errors specifically so you can learn more about the most urgent issues that may be affecting your site.
Semrush Site Audit Errors
As mentioned above, errors found by the Site Audit tool should be set at the highest priority for repair. In other words, don’t ignore them, or you may pay the price with the performance of your site in the SERPs. Errors can reveal a vast array of issues, each one of which is critical to understand.
Here, we’ll look at some of the most important ones.
Pages Returning a 4xx Error Code
4xx errors (such as errors 400, 404 and the like) are all standard. If you are not familiar with SEO errors, these types of errors limit crawling and can impair your site’s crawlability and ability to achieve indexation.
If you impair the basic building blocks of search—crawling and indexing—you hurt your chances of ranking well. And if you have too many of these errors, they may result in what are called crawler traps, i.e. webs of errors that prevent search engine bots from properly crawling your site.
4xx errors are just one category of a family of HTTP request status codes:
- 1xx (informational responses): The request was received and the information is being processed.
- 2xx (successful response): The request was successfully received and accepted.
- 3xx (redirection response): The request must be redirected in order to be completed.
- 4xx (client error response): The request itself was flawed and cannot be understood or accepted.
- 5xx (server error response): The request was valid but the server was unable to understand or accept it.
But 4xx errors are particularly dreaded by SEO practitioners because of their ability to create a poor user experience. After all, no user wants to click on a link only to be shown an error message.
So to address any 4xx errors that Semrush’s Site Audit tool finds, you can try implementing 301 redirects, creating a custom 404 page to keep users on the site or updating the page’s URL if necessary.
Internal Broken Links
When you have internal broken links, you can not only cause 4xx errors, but you can cause a variety of issues related to crawling. From crawler traps to broken pages to indexation problems, they can be the bane of any SEO pro’s existence.
Thankfully, with Semrush’s internal broken links report, you can catch them all and get your internal linking strategy back on track.
From the Site Audit tool’s report, navigate to the Errors section and click on the row pertaining to internal links: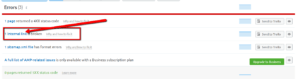
You’ll then arrive on the following page, where you’ll find all the details of the internal links that were found and guidelines on how to fix them:
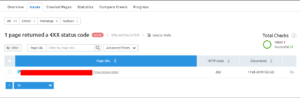
As an added bonus, Semrush is integrated with Trello, a task management system. If you use Trello, this adds a much easier way of implementing the proper fixes within your project management paradigm.
But, how do you really repair internal broken links? There are several ways, with the first being the most obvious—just go to the page with the broken link on it and change it to the correct URL that returns a 2xx (i.e. successful) status code.
Pretty simple, right?
Your other options are to:
- delete the page if the page no longer provides any value;
- implement 301 redirects if the page may still be able to pass link equity; or
- recreate the page to contain the same content as it did before.
As you address each broken internal link, be sure to keep track of your progress for future reference.
Once you successfully fix all your site’s broken internal links, you’ll improve the site’s user experience and thus its chances of ranking higher and gaining even more visitors.
Your Sitemap Has Formatting Errors
There are many potential reasons for an XML sitemap to have formatting errors. For instance, perhaps it:
- doesn’t include the required XML declaration narrative;
- has a line break at the top of the file that’s preventing proper reading;
- has been saved in a format that doesn’t match the proper text encoding declared at the beginning of the file; or
- contains quotes surrounding URLs or other sitemap elements that were added in a program like Word or Excel.
Many of these issues are critical and can make or break your website’s performance in the SERPs.
As if this weren’t enough, there are different kinds of sitemaps that you must maintain, most of them with their own requirements in terms of formatting and creating error-free production files:
- XML sitemaps: These sitemaps are the gold standard for sitemaps nowadays and are easy URL fodder for Google Search Console (GSC).
- RSS, mRSS and Atom 1.0: Blogs with a Really Simple Syndication (RSS) or Atom 1.0 feed can use its URL as a sitemap. A media RSS (mRSS) feed can be used for the site’s video content.
- Text: Sitemaps containing only page URLs can be formatted as standard text documents.
- Image sitemaps: These sitemaps are used to crawl all of the images on your site. New images should be added as they are added to your site.
- Video sitemaps: Video sitemaps should include all of the videos that you want Google to crawl and index on your site. New videos should be added as they are added to your site.
- News sitemaps: This sitemap is for the explicit inclusion of news articles for Google News. It should also be kept updated on a regular basis with new content.
- Mobile sitemaps: These types of sitemaps are built specifically for mobile phones. However, since Google no longer recommends you have separate mobile URLs at all, there’s no need to have a separate mobile sitemap either.
No matter which type of sitemap (or sitemaps) you have, it’s important to make sure that it’s properly formatted and maintained 100 percent of the time.
To help solve the sitemap-related issues that Semrush uncovers, you may want to try using a tool like the XML Sitemap Validator.
Pages Returning a 5xx Error Code
After a 4xx error, the worst kind of HTTP status code you can get is a 5xx error. That’s because they indicate serious bottleneck issues with your server, so they should also be rectified as quickly as possible.
There are many 5xx error codes that you must learn how to decipher, including those related to issues with your HTTPto HTTPS transition.
For example, if you perform a transition and you have 5xx errors, it could be due to your SSL certificate not being live yet. In this case, you may want to contact your server administrator to decipher exactly what’s causing these errors.
Other more serious issues can point to your server itself being misconfigured, and your server throwing errors due to scripts not playing well with each other. One such situation that can cause this is when a plugin is updated on a WordPress site, and that plugin conflicts with another.
As with 4xx errors, 5xx errors can harm both the user experience and your site’s rankings. That’s because they make the site more difficult to navigate for users, as well as more difficult to crawl and index for search engine bots.
5xx errors come in a variety of shapes and sizes, including:
- 500 (internal server error): This is a general error that is generated when the server is unable to fulfill the client request, either due to an unexpected issue or otherwise.
- 501 (not implemented): If a request cannot be processed because it doesn’t support the functionality required to process it, or if the request method is not recognized, you will get a 501 error. It means that some bottleneck is causing the server to not support the request itself.
- 502 (bad gateway): This error displays when the server acts as a gateway, and an invalid response from the upstream server is received when attempting the request.
- 503 (service unavailable): This error happens when a server is temporarily unable to handle the request, especially if it is due to short-term overloading or maintenance.
- 504 (gateway timeout): If a timely response has not been received by the server, this error will be displayed.
- 505 (HTTP version not supported): If this response is served by a web server, this means that there is no support for the HTTP version used in the message request.
- 506 (variant also negotiates): This status code means there is an internal configuration error within the server and that the chosen errant resource is what’s actually configured to engage in the content negotiation. The end result is an incorrect endpoint within the process of negotiation.
- 507 (insufficient storage): When there is insufficient storage, this means that the request cannot be completed because there wasn’t enough storage space to store the required information. The status code is user-based, and thus is only a temporary error.
Other 5xx error codes include 508 (loop detected), 510 (not extended) and 511 (network authentication required).
Whichever 5xx errors you may have, add them to the top of your list of priorities to ensure a positive user experience and efficient crawling.
Missing or Duplicate Title Tags
HTML title tags are a fundamental SEO necessity. If your pages don’t have title tags, Google will be forced to automatically generate titles in the SERPs for them.
This is not an optimal situation because Google can (and does) get title tags wrong.
So it can mess up your conversions in a big way, especially if people skip over your title for not being relevant to their query when in fact your page actually is.
This is why you must have a unique, manually written page title. If you don’t, you increase the possibility that Google will auto-generate a subpar one for you.
When writing your title tags, keep current best practices in mind:
- Stay under 60 characters: Google typically displays the first 50 to 60 characters of a title tag, so you’d be wise to create ones that are 60 characters or less.
- Write for the user experience: Each page’s title tag is the first thing users will see in the SERP results, so you want them to be well-written and intriguing.
- Get creative: Each page should have its own unique title tag to differentiate it and its purpose from all your site’s other pages—no duplicate title tags should exist.
- Include primary keywords: This will help users understand what the page is about.
- Include your brand name: If you want to build brand awareness and recognition, start putting your brand name in each title tag.
Duplicate Content Issues
Duplicate content is a serious but all-too-common issue. From things like using the same location information across all a site’s location pages to copying blog posts into an archive, it’s easy to inadvertently create duplicate content that may harm your rankings.
But because duplicate content is so common, there are many straightforward ways to fix it. Depending on the situation, you can:
- use the canonical tag;
- use 301 redirects;
- delete the duplicate content entirely;
- avoid using separate mobile URLs; or
- tweak the settings on your content management system (CMS).
Also bear in mind that duplicate content is an ongoing concern for every website, so it’s important to keep track of it over time too.
Pages Could Not Be Crawled
This issue arises when search engine bots are unable to properly crawl your site’s pages. Since site crawling forms the very foundation of how search engines work, you can’t afford to let crawling issues go unaddressed.
To enhance your site’s crawlability, try:
- ensuring your CMS isn’t disabling or discouraging crawling or indexing;
- publishing new and unique content on a regular basis;
- preventing duplicate content;
- steering clear of Flash (hey, I’m not thrilled that a part of my college certificate is now invalid either);
- checking to ensure that you haven’t blocked crawling in your robots.txt file;
- keeping an eye out for index bloat, which can eat up your crawl budget;
- improving your site’s page speed;
- striving to achieve mobile-friendliness;
- organizing your site’s pages in a logical manner;
- optimizing your site’s JavaScript and CSS elements; or
- streamlining your sitemap.
Once your pages are perfectly crawlable, you’ll have one of the biggest SEO hurdles out of the way.
Broken Internal Images
Even internal broken images can be a big issue when not handled correctly.
Why do images tend to go missing on websites? The reasons are varied, but there are several. Images can:
- be deleted or moved from their initial location;
- get renamed;
- experience permission changes.
If any of those things happen, then your website’s users will have problems any time they even attempt to view content with missing images.
There are multiple ways to ensure your site doesn’t suffer from the consequences of broken images:
- If an image does not exist at its regular location, be sure to update the URL.
- If an image was deleted, damaged or is otherwise irreparable, replace the image with a new one.
- If you no longer need an image, just remove the image from the page’s code.
Integrating these best practices into your overall workflow will help make sure that your site doesn’t suffer from major issues that can occur when broken images get out of hand.
Pages Have Duplicate Meta Descriptions
Meta descriptions that are duplicate have similar effects as duplicate title tags and are a definite no-no in terms of SEO best practices. You should always use completely unique page titles and meta descriptions for every page you create.
So what are the standard best practices for creating awesome meta descriptions?
Write a Unique Meta Description for Each Page
This practice is important enough that it bears repeating: No matter what, you should create a one-of-a-kind meta description for every page you publish.
If you have not yet integrated this essential best practice into your workflow, you should be. If you have already published many many hundreds of pages without doing this, start with your most important ones and work your way through.
With a site built on WordPress, you can install Yoast’s SEO plugin to help. It’s an easy, simplified way to make sure that you write meta descriptions with the right length. It will even show you a preview of your snippet in the SERPs, so you can figure out whether or not it will work for you ahead of time.
Don’t be afraid to experiment with different phrasing, keyword phrases, and calls to action. There are as many variations of the meta description out there as there are people, and you will only hurt yourself if you stick to creature-of-habit thinking.
Make Sure Your Meta Description Is Between 150–155 Characters
If your meta description is not the right length, it will be cut off by an ellipses (…) within the SERPs. This is not a good thing as you want your readers to see the full and complete meta description when they encounter your listing.
When the meta description is cut off in the SERPs, it creates a layer of mystery and intrigue that is not beneficial from a marketing perspective.
Also consider that the length of your meta description in the SERPs will change based on things like your user’s screen size, the type of device your audience is using, not to mention other technical factors.
Moz has seen Google cut off meta descriptions exceeding 155–160 characters in length, so we recommend staying in the 150–155 range to be safe.
Include the Page’s Targeted Keyword in Your Descriptions
While Google doesn’t use keywords in meta descriptions as a ranking factor, it does emphasize them in the SERPs:
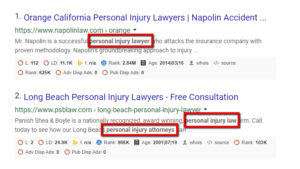
This is especially true when the user’s phrasing is matched. This doesn’t prove anything conclusively in terms of ranking, but it does indicate that your users will notice your result more easily when they are scanning the page looking for results that are aligned with their search query.
So, including pages’ primary keyword in their meta descriptions can help create a better user experience.
Improper Robots.txt Formatting
Even formatting errors in your robots.txt file can cause major issues with your SERP performance.
From indexing issues and not being included in the search results, these can wreak havoc on your site if left unchecked.
You should review your robots.txt file on a regular basis in Semrush and make sure that you don’t have any major issues.
Aside from that, the most common robots.txt issues include the following:
Incorrect Syntax
It is important to note that a robots.txt file is not required to enable standard crawling behavior. However, normal crawling behavior can be inhibited and even stopped completely when the wrong robots.txt syntax is present.
For instance, let’s say you’re using the following code:
User-agent: Googlebot
Disallow: /example_directory/
In this example, you have disallowed Google’s crawler from crawling the entire /example_directory/. To apply this rule to all crawlers, you could use the following code:
User-agent: *
Disallow: /example_directory/
Basically, the asterisk is a wild card. This serves as a variable in the user-agent declaration that says all spiders. So if you wanted to stop Googlebot from crawling but didn’t want to stop Bingbot, just one small asterisk could land you in hot water.
One other major issue that is commonly found in robots.txt files (at least, those that I run into regularly in website audits) involves code that looks something like this:
User-agent: *
Disallow: /
Just the addition of the forward slash here prevents the entire website from being indexed.
This is why it is so important to know your syntax and make sure that what you are doing won’t have unintended consequences.
To make doubly sure your syntax is correct, you’d be wise to use Google Search Console’s robots.txt testing tool before making any changes.
The Robots.txt File Isn’t Saved to the Root Directory
One way you can truly mess up your site’s crawlability is by not saving its robots.txt file to the root directory.
On some servers, the root directory is public_html. On others, it can be /root. On still others, it can be /your_username/public_html/.
Whatever the case, you must understand your web server’s structure and make sure that you are saving your robots.txt file to the right place. Otherwise, even this simple error can cause major issues.
Your Sitemap Contains Incorrect Pages
We’ve already covered improper sitemap formatting, but it’s equally important to ensure your sitemap doesn’t contain incorrect page URLs.
Semrush says that “only good pages intended for your visitors should be included in your sitemap.xml file.”
Errors that trigger this error in Semrush’s Site Audit tool include:
- URLs leading to web pages with the same content;
- URLs redirecting to different pages; or
- URLs returning a non-2xx HTTP status code.
When these types of URLs exist in your XML sitemap, Semrush says that they “can confuse search engines, cause unnecessary crawling or may even result in your sitemap being rejected.”
So, the creation of your sitemaps should be fairly straightforward. Following these rules should lead to a mostly-perfect XML sitemap almost every time:
- Always make sure all URLs return 2xx status codes, and never include URLs that have 4xx errors or 5xx server errors.
- Do not include URLs that are redirects.
- Do not include URLs that are soft 404s (these are URLs that return 2xx codes but do not return any content).
- Do not forget to check for any syntaxial errors and coding errors.
Your Pages Have a WWW Resolve Issue
Usually, you can successfully access a webpage whether you add WWW to the domain name or not.
Nevertheless, if both versions are crawled and you allow both to be displayed on your site, you leave open a major duplicate content issue that can in turn cause SERP performance issues. Doing so will also dilute link equity by splitting it between each version.
So you should be specifying the version (either with the WWW prefix or without) that should be prioritized, so that only one version is crawled.
Your Pages Have No Viewport Tag
If you are not familiar with web development, the meta viewport tag is what allows you to control your webpage’s size and scale when using a mobile device.
This tag is a best practice for modern web development, and it’s required if you want to take advantage of a responsive site design.
So, be sure that each page has one and is displaying properly on mobile devices.
W3Schools also recommends that you:
- refrain from using large fixed-width elements;
- don’t allow content to rely on a specific viewport width to render properly; and
- use CSS media queries to apply appropriate styling for screens of varying sizes.
Your Pages’ HTML Is Too Large
The full HTML size of a page refers to all of the HTML code that is contained on that page.
If the page is too large (exceeding 2MB, for example) this can lead to drastically reduced page speed, results in bad user experience, and a lower search engine ranking.
As someone who began my career in web development, I am of the opinion that any developer should get started by creating pages with tight requirements such as the following:
- the page size is less than 32KB;
- the page only uses 256 colors;
- all solid-color vector graphics should be coded where it makes sense in the design (no images);
- the page loads in less than half a second on a 56K modem;
- the page is only allowed to use OS-based fonts (no Google fonts;
- JavaScript is limited to one file; and
- CSS is limited to 1 file.
For example, a three-row, two-column page layout structure should only have five <div> elements, entirely coded to be responsive with CSS in the linked stylesheet. The total lines of code should max out at 50–100.
Once this is accomplished, the developer can then move on to more complex layouts and sites, content in the knowledge that they can optimize said files down to that level if they need to.
There are other best practices you should follow if you want to create the cleanest site with the least amount of code possible, such as those outlined by WebFX. You can also further reduce the size of your pages’ code by using an HTML minifier.
Your AMP Pages Have No Canonical Tag
To prevent duplicate content issues with your Google AMP and non-AMP pages, it’s crucial to use the canonical tag to indicate which version should appear in search results and which should not.
If you’ve already adopted AMP without implementing the canonical tag, then you may have some work to do to get your site to a healthier place.
If you haven’t adopted AMP but are considering it, be sure to weigh the pros and cons first. For instance, while AMP is capable of significantly increasing page speed on mobile devices, it also comes with severe design restrictions.
Read through Google’s own AMP guidelines to fully understand all the other requirements that AMP entails.
There Are Issues with Hreflang Attributes
For sites that are going international, hreflang attributes are a must. That’s because when they want to have multiple locations, they solve their issues with multiple pages for multiple languages by using hreflang.
This implementation helps differentiate language pages so that they are not seen as duplicate content.
When used correctly, hreflang can be a powerful addition to your site. But when errors come up, it can cause big issues.
Semrush will alert you if:
- your country code is not in the ISO_3166-1_alpha-2 format; or
- your language code is not in the ISO 639-1 format.
To solve those issues, ensure both your country and language codes are properly formatted according to the listed ISO standards.
Note that Semrush will also generate an error if your hreflang attributes conflict with your source code. To avoid such a situation, always avoid:
- conflicting hreflang and canonical URLs;
- conflicting hreflang URLs; and
- non-self-referencing hreflang URLs.
Finally, also make sure that none of your site’s hreflang URLs point to broken pages.
There Are Non-Secure Pages
While it is considered a standard SEO practice nowadays to use the HTTPS protocol on websites, it doesn’t always happen. In fact, some pages exist where the webmaster includes a contact page on an insecure site!
This is the reason why this issue triggers an error from Semrush when it shows up in an audit. If a site’s pages are not secure but have elements that should be secured, they present big risks for users who submit their information or otherwise interact with them.
Google Chrome will even display a “Not Secure” warning in users’ address bar when they access a non-HTTPS site, as will Firefox and other popular browsers.
So, you need to secure your website with HTTPS if you want users to feel comfortable using it.
Your Security Certificate Is Expired or Expiring
This issue illustrates why it’s so important to keep up with maintenance on your SSL certificates.
If your security certificate is expired or is about to expire, users visiting your site will be issued a warning from their browser. On Chrome, for instance, users will see a page proclaiming your connection is not private when attempting to visit a site with an invalid security certificate:
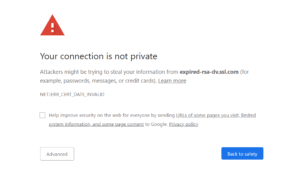
The best way to fix this issue is to make sure that you either fix the expired or expiring certificate yourself, have your web server set to automatically do it or have your webmaster do it for you.
There Are Issues with an Incorrect Certificate Name
Yes, even seemingly insignificant details in registering your SSL certificate will cause issues with your website.
If you have one letter off, causing the certificate to not match your website, web browsers will not display your site to users. Instead, a name mismatch error will be displayed, and this can turn away visitors and have a negative impact on your organic search traffic.
If your SSL certificate isn’t issued to your site’s exact URL, Semrush will display an error so you can address the problem accordingly.
There Are Issues with Mixed Content on Your Pages
As Google explains it, “mixed content occurs when initial HTML is loaded over a secure HTTPS connection, but other resources (such as images, videos, stylesheets, scripts) are loaded over an insecure HTTP connection.”
How do you fix this kind of issue? The typical way is to change all HTTP-based content to HTTPS-based content. You can also avoid this by using relative URLs when linking to your on-site assets rather than absolute URLs.
To discover more techniques for fixing the mixed content Semrush brings to your attention, check out Google’s detailed guide on the topic.
Remember, most browsers will block mixed content altogether in the interest of users’ safety, so it’s vital for you to remedy it as soon as possible—your conversions may depend on it.
There Is No Redirect or Canonical Tag Pointing to the HTTPS Homepage from the HTTP Version
When you have more than one version of your homepage serving the same content, this creates duplicate content and confuses the search engines trying to index it. They are unable to make a decision on which page it should index, and which one to prioritize in the SERPs.
This is a critical issue with any type of content, but especially with a site’s homepage. If search engines don’t know which version of the homepage to show users, the site may lose both rankings and traffic.
So, be sure to use a 301 redirect or canonical tag to instruct search engines to index the HTTPS version of your site’s homepage. This will help ensure that you have a high-performing site and don’t experience any major conflicts during your own HTTP to HTTPS migration.
Remember, even seemingly small details in technical implementations can have a major sitewide impact if you are not careful.
You Have Issues with Redirect Chains and Loops
Let’s not forget that performing 301 redirects—redirecting one URL to another—is the right thing to do in many situations.
However, if your redirects are incorrect, they can lead to serious, disastrous results. Examples of these kinds of errors include redirect chains and loops, also known as spider or crawler traps.
In other words, when a search engine bot gets stuck in a cycle of redirects, it can’t properly crawl the pages it needs to and as a result the site won’t be properly indexed.
Not sure why you’re getting this error in the first place? Semrush says that “if you can’t spot a redirect chain with your browser, but it is reported in your Site Audit report, your website probably responds to crawlers’ and browsers’ requests differently, and you still need to fix the issue.”
Your Pages Have Broken Canonical Links
You already know that the canonical tag is a fantastic tool for ensuring that search engines display the correct page in search results. But you also need to remember to check that the URLs you add to your canonical tags aren’t broken.
When canonicals don’t lead to 2xx-OK URLs, it complicates the crawling process because when there are too many 4xx or 5xx errors in the canonicals, crawlers hit a brick wall and can go no further. You can only imagine what this can do to your crawl budget.
Broken canonical links also present a problem in terms of link equity, since a page can’t pass authority to one that doesn’t exist.
Pages Have Multiple Canonical Tags
Yes, even pages with more than one canonical tag can be major issues for a site. Here’s why: Multiple canonicals make it nearly impossible for any search engine to identify which URL is the preferred one.
This leads to confusion and unnecessary loss of crawl budget and can result in the search engines either ignoring the tags or picking the wrong one.
In Google’s case, all the canonical tags will simply be ignored. As stated on the Search Central blog, “specify no more than one rel=canonical for a page. When more than one is specified, all rel=canonicals will be ignored.”
If Semrush alerts you that some of your site’s pages have multiple canonical tags, it’s imperative that you immediately eliminate all but one.
There Are Broken Internal JavaScript and CSS Files
While we have gone over other issues with JavaScript and CSS files already, it’s important to highlight the fact that these files are critical to making sure that your site is working and displaying properly.
If you don’t do proper maintenance and a script stops running on your site, you can run into major issues down the line if it is not fixed immediately.
While it may not immediately result in a rankings drop, these files can eventually impact search performance because search engines will not be able to properly render and index your pages.
Several issues can arise as a result of broken JavaScript and CSS files. For example, let’s say you’re using two JavaScript plugins for a WordPress site. One plugin is updated, while the other is not. Suddenly the two plugins don’t agree with each other and the worst happens: The site goes down until the problem is resolved.
That’s why I can’t stress enough the importance of making sure that your JavaScript and CSS files play nice with each other. If you don’t, you run the risk of this type of issue happening, and potentially taking down your site overnight.
Secure Encryption Algorithms Aren’t Supported by Your Subdomains
Semrush says that this issue is triggered by their software when they connect to the server and find that it’s not using updated encryption algorithms.
It is likely that some browsers will warn your users of the issue when they are accessing insecure content, and this can then translate to public mistrust, which will cause them to not feel safe enough to use your site.
So, it’s vital to not only implement but stay up to date with the best encryption methods. These include the Advanced Encryption Standard (AES), the Rivest-Shamir-Adelman (RSA) algorithm and the Twofish algorithm.
Your Sitemap Files Are Too Large
This issue comes from two limits that are in place for sitemap files. These files should not exceed the following, otherwise they will show up on your Site Audit report as being an issue:
- Your sitemap should not contain more than 50,000 URLs.
- Your sitemap file should not exceed 50MB.
Either issue can weigh down your XML sitemaps, therefore causing further issues with crawling and indexing.
If your site is simply too large to get your sitemap down to an acceptable size, take Google’s advice and use several smaller sitemaps instead of one giant one.
Your Pages Load Too Slowly
Google introduced page speed as a ranking factor for desktop searches in 2010, and did the same for mobile searches in 2018. If that doesn’t tell you that page speed matters a lot, we don’t know what will.
So if your Site Audit report returns an error about slow page speed, you need to find a solution as quickly as possible. You can start by:
- validating your code with W3C’s markup validation service;
- install a WordPress caching plugin;
- work on improving your site’s video and image optimization;
- use asynchronous loading;
- minify your page’s JavaScript, CSS and HTML code;
- disable WordPress pingbacks and trackbacks; and
- start using a content delivery network (CDN).
Fix Lots of Errors in Semrush’s Site Audit Tool to Get One Great Result
When you’re learning about and working to resolve the issues revealed by the Site Audit tool, it’s easy to get overwhelmed.
But rest assured that the fruits of your labor will be worth it: By remedying whatever errors are present, you’ll be able to enjoy better rankings, more satisfied visitors and even higher conversions.
Image credits
Screenshots by author / January 2021