- Errors are the most urgent types of issues and should be resolved as soon as possible.
- Warnings are less severe issues and can be addressed after errors.
- Notices may not be actively harming performance at all, but should still be inspected when you get the chance.
Table of Contents
- Site Audit Notices
- Pages Have More Than One H1 Tag
- Subdomains Don’t Support HSTS
- Pages Are Blocked From Crawling
- URLs Are Longer Than 200 Characters
- Outgoing External Links Contain Nofollow Attributes
- Robots.txt Not Found
- Hreflang Language Mismatch Issues
- Using Relative URLs in Place of Absolute URLs
- Your Site Has Orphaned Pages
- Pages Take More Than 1 Second to Become Interactive
- Pages Blocked by X-Robots-Tag: Noindex HTTP Header
- Blocked External Resources in Robots.txt
- Broken External JavaScript and CSS Files
- Pages Need More Than Three Clicks to Be Reached
- Pages Have Only One Incoming Internal Link
- URLs Have a Permanent Redirect
- Resources Are Formatted as a Page Link
- Links Have No Anchor Text
- Links to External Pages or Resources Returned a 403 HTTP Status Code
Site Audit Notices
Creating a website involves several technologies and processes, all of which are not always perfect. During the development process, errors can seep through. These errors, while not necessarily indicative of a site gone seriously wrong, can be indicative of lazy development processes. Thankfully, there is Semrush. With Semrush, there are a number of high-priority errors and less urgent warnings you can uncover using their Site Audit tool. Here, we’ll go over Site Audit notices. These are the lowest priority of items you must identify and repair in order to ensure that your site functions well from both a search and development perspective. Below is a screenshot showing the notices section of Semrush’s Site Audit tool. Click on it and you’ll see all the notices Site Audit has found for your site: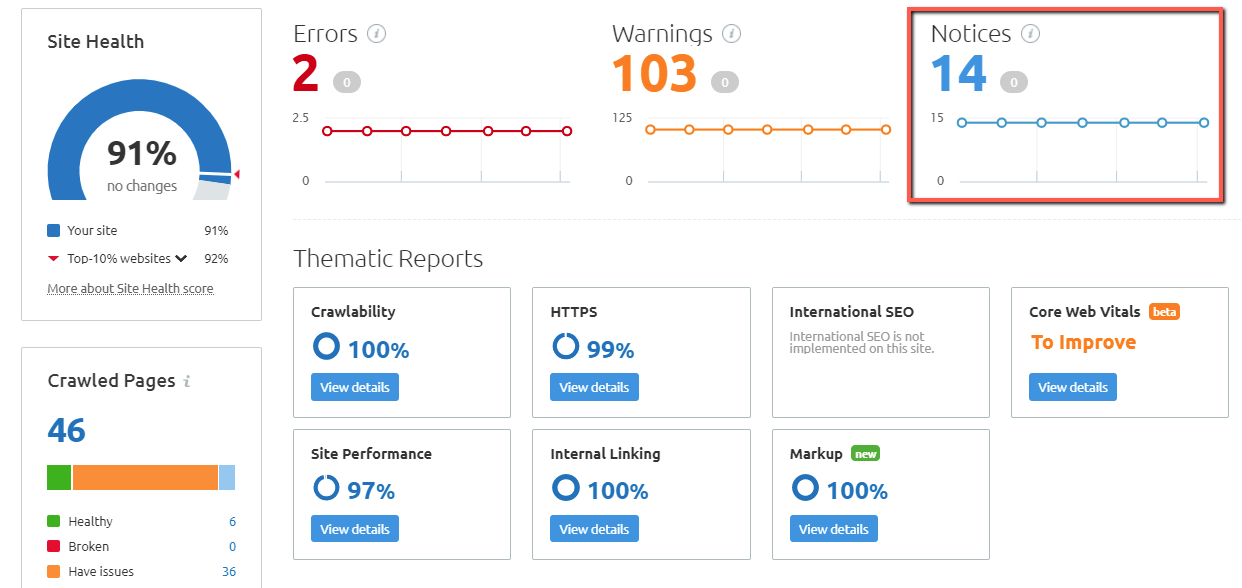 While these notices aren’t necessarily critical issues that you have to address right away, you’ll still want to check on them whenever you get the chance. If left unchecked, some can even cause significant technical performance issues down the line. Ahead, we’ll examine some of the most important notices the Site Audit tool can serve.
While these notices aren’t necessarily critical issues that you have to address right away, you’ll still want to check on them whenever you get the chance. If left unchecked, some can even cause significant technical performance issues down the line. Ahead, we’ll examine some of the most important notices the Site Audit tool can serve.
Pages Have More Than One H1 Tag
When developing a site, developers may have one goal in mind: to develop the site using whatever code will get the job done, even if it’s not compact or even 100% percent correct. This is because for most sites, developers want to ensure that the final product is delivered to the client on time. Sometimes, this leads to cutting corners. What happens in these instances is the addition of more than one tag that may not be semantically accurate. Semrush does not recommend having more than one H1 tag. While Google is on record as saying that having more than one H1 tag will not harm your SEO efforts, to keep things simple, accurate and confusion-free on the part of the search engine you’d still be wise to stick to a single H1 tag. This is because the H1 header tag establishes the main thematic topic of your page. The H2 header tag establishes supporting topics, and the H3 header tags may establish supporting topics (such as lists). In addition, another issue arises when H1 tags are not properly considered in their semantic order. This issue occurs when developers use H1 tags as decoration, rather than structural tags. It’s not considered correct, developmentally-speaking, to use header tags as tag styles.Subdomains Don’t Support HSTS
HSTS, or HTTP Strict Transport Security, is a critical component of a correct, secure HTTPS implementation. However, it’s not always enabled on a server by default. In order to ensure the best possible security, you must make sure that HSTS is a part of your HTTPS system. AsMozilla explains, the HSTS header “informs the browser that it should never load a site using HTTP and should automatically convert all attempts to access the site using HTTP to HTTPS requests instead.” The best way to repair this issue is to add an HSTS directive to your site’s server files. On Apache servers, this is usually done in the .htaccess file. As GlobalSign elaborates, this can be accomplished simply by pasting the following code into your .htaccess file: # Use HTTP Strict Transport Security to force client to use secure connections only Header always set Strict-Transport-Security “max-age=300; includeSubDomains; preload” On NGINX, you may need to add a more advanced directive. Either way, the end result is the same: HSTS will be implemented on the site.Pages Are Blocked From Crawling
This is an issue that must be addressed at some point, although urgency depends on severity. If you have a significant portion of the site blocked, then you may want to consider unblocking it. For example, category pages shouldn’t always be blocked from crawling by Google. On the other hand, individual pages that are traditionally blocked—such as thank you pages and the like—are not a concern if they are shown in this list. Semrush will bring up everything falling under this issue without discrimination. It’s up to you to analyze the blocked pages and determine which are posing a critical issue that must be addressed. This is why just blindly following issues and checking them off in Semrush is not something that is to be taken lightly. For example, let’s say you find that approximately 15,000 pages are being blocked on an e-commerce site. The site only has 50 pages and 1500 products, so there should be no way that it should have so many pages to begin with. As it turns out, its pages used to number in the 1,000s because of parameter-related issues, and all of the parameter pages were simply dumped into the robots.txt file and blocked. So, you may want to leave the block intact. However, if the pages were blocked unnecessarily and they no longer exist, then you can repair the issue by unblocking them—Google will automatically discount 404 pages anyway.URLs Are Longer Than 200 Characters
John Mueller has stated in no uncertain terms that URL length doesn’t affect pages’ Google rankings: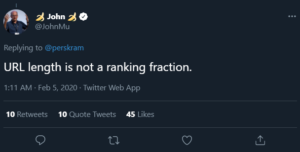
URL length is not a ranking fraction.
— 🍌 John 🍌 (@JohnMu) February 5, 2020
Outgoing External Links Contain Nofollow Attributes
There is an ongoing belief among SEO practitioners that external links require a nofollow attribute. However, this is simply a myth. Unless your page contains external links to disreputable sites that you do not endorse, such as those that you’ve paid for a backlink (please don’t do this!), you don’t have to add a nofollow attribute to those external links at all. After all, you always want to have an editorial vote of confidence for the links you place on your page. If you don’t, you have a problem. There are also new nofollow rules to consider. For example, nofollow is treated as a hint rather than a directive as of March 2020. This change brought with it additional attributes you can add to your links, such as rel=”ugc” (to indicate that the link points to user-generated content) and rel=”sponsored” (which indicates that the link is paid). You can see them all in Google’s guidelines for qualifying outbound links. As a rule of thumb, just remove the nofollow attribute from external links. If the site you’re optimizing is fairly large, and you inherited it from a shady SEO practitioner who wanted to add a nofollow attribute to all external links no matter what, you can simply perform a find and replace in the WordPress database. Otherwise, you can edit HTML files in this manner. For instance, you’ll be able to do so with the JavaScript String replace() method.Robots.txt Not Found
The robots.txt file is a file that sits at the root of your web server. It is responsible for telling bots like Googlebot how they are allowed to crawl your website. If your site is missing a robots.txt file, this isn’t an issue in and of itself. But if you typically have a robots.txt file on your website, and you also have significant issues from bots and spiders, then you may want to restore it. On the other hand, if there are no issues from bots and your site is being crawled and indexed just fine, then it’s probably not a critical issue. In the interest of being thorough, though, you will want to include a robots.txt file with the following lines at the root of your server. Just create a new text file and insert these lines of code:Disallow: Sitemap: https://www.domainname.com/sitemap.xmlThis allows all spiders to crawl your site without issue, and also allows them to easily find your sitemap file. Be careful with your syntax. Unless you really mean it, do not ever use Disallow: / with a forward slash. This will cause your server to exclude all search engines, which is almost certainly not a good thing.
Hreflang Language Mismatch Issues
You would be surprised how often hreflang tagmismatch issues come up in audits. Whether they are caused by including the wrong language code in the header or the improper implementation of hreflang links, these can be disastrous for your hreflang implementation as a whole. Errors that can impact your hreflang implementation include the following:Incorrect Language Code
Using the wrong language code is one of the most common (and easier) mistakes to make when it comes to hreflang errors. Ideally, the code must be inISO 639-1 format. If it is not in this format, then it will be considered an invalid language code.Self-Referencing (or Return) Hreflang Tag is Missing
You must also make sure that you include a self-referencing hreflang tag when you create your hreflang implementation. Google discusses the issue in-depth here, but John Mueller summed it up best in 2018 when he stated that self-referencing hreflang tags aren’t necessarily required but are nonetheless a good idea to include:Using Relative URLs in Place of Absolute URLs
As a rule, you must use absolute URLs rather than relative URLs in all links that are listed within hreflang tags. Many issues arise if a site uses relative URLs because they do not indicate to bots which URLs you actually want to have crawled. If you don’t use absolute URLs, you also run the risk of creating code errors. When they get out of hand, all of these issues can cause serious problems when you implement them incorrectly on-site. This is where regular checking of notices will come in handy. The following example shows the difference between correct and incorrect versions of these URLs: https://www.domainname.com/en-us/pagename/ (correct) /en-us/pagename/ (incorrect)Your Site Has Orphaned Pages
By definition, orphaned pages are those that have no internal links pointing to them. Ideally, all pages on your site should have at least one internal link. The reason why orphaned pages are a problem is because if you have a page that has valuable content but it has no links, then you’re missing an opportunity to drive link equity to that page. The recommended fixes from Semrush for orphaned pages are basically to remove the pages if they’re no longer needed. But if the page is valuable and is bringing in plenty of traffic, you will want to instead add an internal link to it elsewhere on the site. Of course, the other perspective is also true – if the page is needed, but it doesn’t require any internal linking whatsoever (such as a Terms of Service or thank you page) you are free to leave it as-is.Pages Take More Than 1 Second to Become Interactive
In general, page speed should be limited to no more than two to three seconds. However, Google’s Maile Ohye stated that although two seconds has been cited as an acceptable threshold for ecommerce website acceptability, Google aims for a response time of half a second or less: While this is a quote from 2010, it illustrates the fact that even back then, page speed was both a key performance metric and an important factor of the user experience. Don’t just blindly view a loading time of two to three seconds (or a score of 70 or more on Google’s PageSpeed Insights tool) as the be-all and end-all of page performance. Instead, look at different tools and use those tools as benchmarks for how your site is really performing. One tool could be very different from another, so it’s important to understand some of the inner workings about said tool as you work on page speed. In order to check whether or not you have issues with this, you must connect your Google Analytics account with Semrush. This will import data into Semrush, allowing you to diagnose issues within the pages triggering this error. Using PageSpeed Insights, here is an example of a website that has a 19.8-second time to interactive: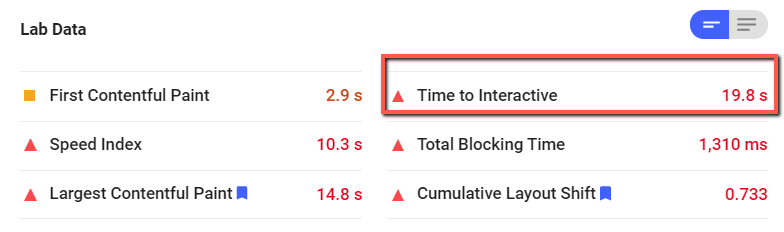
Pages Blocked by X-Robots-Tag: Noindex HTTP Header
When you have this issue, you have an X-Robots-Tag blocking pages from being indexed in your HTTP header code via the noindex tag. Google offers the following code as an example of the X-Robots-Tag: Google also lists several additional directives that you can use in your HTTP headers. They are all useful, and can be used in place of your standard noindex tag.
Google also lists several additional directives that you can use in your HTTP headers. They are all useful, and can be used in place of your standard noindex tag.
Blocked External Resources in Robots.txt
Believe it or not, there are situations that arise during audits where there are external resources being blocked in robots.txt. In most cases, there isn’t a valid reason for doing this. Usually, they are simply accidental blocks. However, there are a few reasons why you might want to intentionally do something like this. For instance, you may have:- files on another server that are necessary for the operation of the design, but do not necessarily affect the existing display of the site;
- external font files that you don’t want to send a search engine to; or
- other external plugin files that you don’t want to send a search engine to (such as critical files that may interfere with the operation of a plugin).
Broken External JavaScript and CSS Files
There are situations that come up when your JavaScript (JS) and Cascading Style Sheets (CSS) files are entirely broken. This may be due to updated plugins that simply don’t play right with each other, or it could be because the resource serving the external CSS file (such as a font file) is no longer active. In this case, you’ll need to remove the code responsible for calling these files. Other situations where broken external JS and CSS file repairs may be warranted include those where:- external JS files are being controlled by a third party;
- updated plugins no longer work correctly with the old implementation; and
- any JS or CSS files hosted on a content delivery network that are now broken.
Pages Need More Than Three Clicks to Be Reached
This issue comes down to your website’s architecture. The theory goes that the shallower the crawl depth, the better (and easier) it will be for Google to crawl your site. In SEO terms, excessive crawl depths can pose significant issues for your SEO efforts. This is why Semrush recommends that pages with more important content should never be more than 3 clicks deep from your home page. John Mueller has echoed this, and has mentioned that while Google doesn’t count the slashes in URLs, it does view pages as being less important if they take many clicks to reach from the homepage: In other words, the less clicks it takes for a user to get to a page from your site’s home page, the better. It’s up to you to determine how to keep crawl depth under control while simultaneously maintaining a logically organized site structure. Also keep in mind that making sure that your content is approximately three clicks away from the home page does not mean that you’re not using a siloing architecture—this is an important distinction. You can still have content three clicks away from the home page and also have a siloing architecture at the same time.Pages Have Only One Incoming Internal Link
When your pages have only one incoming internal link, you’re losing opportunities to achieve traffic from more heavily-trafficked pages. In other words, don’t bury important pages deep within your site. After all, the main goal of internal linking is to make sure that Google is capable of finding the pages you want it to. You can’t expect Google to randomly find your page without an adequate number of internal links (unless you submit a sitemap file in Google Search Console on a regular basis, but that’s another issue altogether).URLs Have a Permanent Redirect
Permanent redirects are fine. They are a critical component to good SEO, especially during a site migration. Migrating a site may require several redirects at one time. The key is making sure that you don’t have more than two or three hops—five at the most. Anything beyond that becomes excessive and can cause significant confusion in Google’s eyes. In January 2020, John Mueller advised site owners that less than five hops in a redirect chain is preferred. In response to a Reddit post from the user dozey:Resources Are Formatted as a Page Link
This issue occurs when resources like images are added in WordPress, and a second link to another page is added in addition to that resource. When using links in this manner, link equity is going to waste. Why? Instead of powering another page, link equity is sent to a resource that may or may not appear on Google. It’s better to strategize your link equity and where it goes to avoid these resources receiving link equity that would be better spent elsewhere. Here’s a brief example of this error: In about 99 percent of cases, it does not make sense to include a link to the image in such a fashion.
In about 99 percent of cases, it does not make sense to include a link to the image in such a fashion.
Links Have No Anchor Text
Links may be the foundation of the internet itself, but it’s anchor text that determines how users view them. This is what anchor text looks like to your site’s visitors, as seen in our article on Google’s domain information feature: Anchor text helps power the context of your links, so strategically thinking about them in this manner is critical. There is another point to consider on this as well: Using generic anchor text like read more is not optimal. Instead, it’s better to use the page’s title or a descriptive phrase that gives users a clear idea of what they’re clicking on. When you include useful anchor text that’s readable by both users and search engines, your links can benefit.
Anchor text helps power the context of your links, so strategically thinking about them in this manner is critical. There is another point to consider on this as well: Using generic anchor text like read more is not optimal. Instead, it’s better to use the page’s title or a descriptive phrase that gives users a clear idea of what they’re clicking on. When you include useful anchor text that’s readable by both users and search engines, your links can benefit.