Google may be a tech industry colossus (the kraken of search engines does have a certain ring to it), but even its most robust algorithms aren’t perfect. Mistakes are made, crawlers get stumped and some pages inevitably fall through the cracks. While typical internet users may never notice them, these crawlability errors can have a big impact on SEO practitioners and the results they’re striving to achieve.
What does this mean for you as an SEO pro? It’s your job to make a site as crawlable as possible. Make it easier by assessing and improving a site’s crawlability with an arsenal of targeted techniques designed to guide Googlebot on its merry way.
- What Is Crawlability?
- Check CMS Settings
- Reduce Index Bloat
- Maximize Page Speed
- Be More Mobile-Friendly
- Fix Broken Pages
- Organize Blog Pages
- Optimize JavaScript and CSS
- Tidy up the Sitemap
What Is Crawlability?
Before Google can add a site to its index and assign it a ranking, it has to crawl the site.
Crawling is the automated retrieval of a site’s content, whether in the form of text, videos or images. Once it’s crawled a site, Google adds each page’s information to its index and analyzes it using algorithms.
The crawling process is executed by Google’s bots, collectively (and perhaps affectionately) referred to as Googlebot. On every page it visits, it diligently scans content and follows links, eventually creating a comprehensive overview of the entire site.
Its job isn’t always a walk in the park, though. From explicit crawling blocks to accidental 404 errors, plenty of obstacles can get in the way. The ease with which Google can crawl a given page is called crawlability. The fewer obstacles a page contains, the more crawlable it is.
Fortunately, site crawlability isn’t outside your control. Implement a few simple tactics to expedite the crawling process, and you’ll pave the way for better rankings and more clicks.
Check CMS Settings
If a site isn’t being crawled as frequently or efficiently as it could be, the solution may be as simple as toggling a setting in its content management system (CMS).
Every major CMS includes an option to dissuade search engines from crawling or indexing a site. In WordPress, mouse over Settings in the left-hand navigation bar, choose the Reading option, and check the box next to Search Engine Visibility:
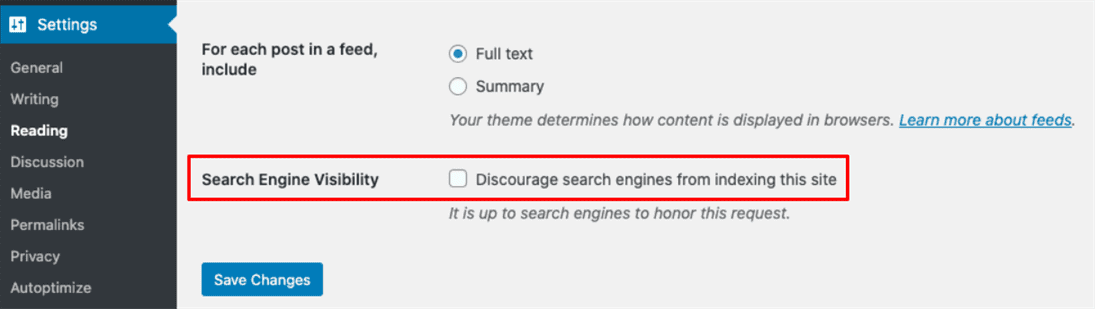
Or, you can manually edit the site’s robots.txt file for the same result. Squarespace also allows users to discourage indexing via either the settings or robots.txt file, while HubSpot users can only disable indexing via robots.txt.
If your goal is to make a site more crawlable, verify these settings. It’s quick and easy, and might provide a one-click solution to your crawlability issues.
Reduce Index Bloat
No, not the kind of bloating you get after a wild night at Taco Bell. We’re talking about index bloat, a problem that arises when Google indexes pages it shouldn’t. Index bloat can cause a site’s most valuable pages to be overlooked in favor of obsolete, irrelevant or duplicate ones.
The headaches don’t end there. In the case of large sites, index bloat can devour crawl budget faster than you can say, “chalupa overload.” In case you need a refresher, crawl budget refers to “the number of URLs Googlebot can and wants to crawl.” Put differently, if Google starts crawling a glut of pages it shouldn’t, higher-quality pages might not get the attention they deserve.
To check for index bloat, verify how many pages a site has listed in its sitemap, perform a Google search for pages within the site (using the format site:www.example.com) and note the number of results Google returns:
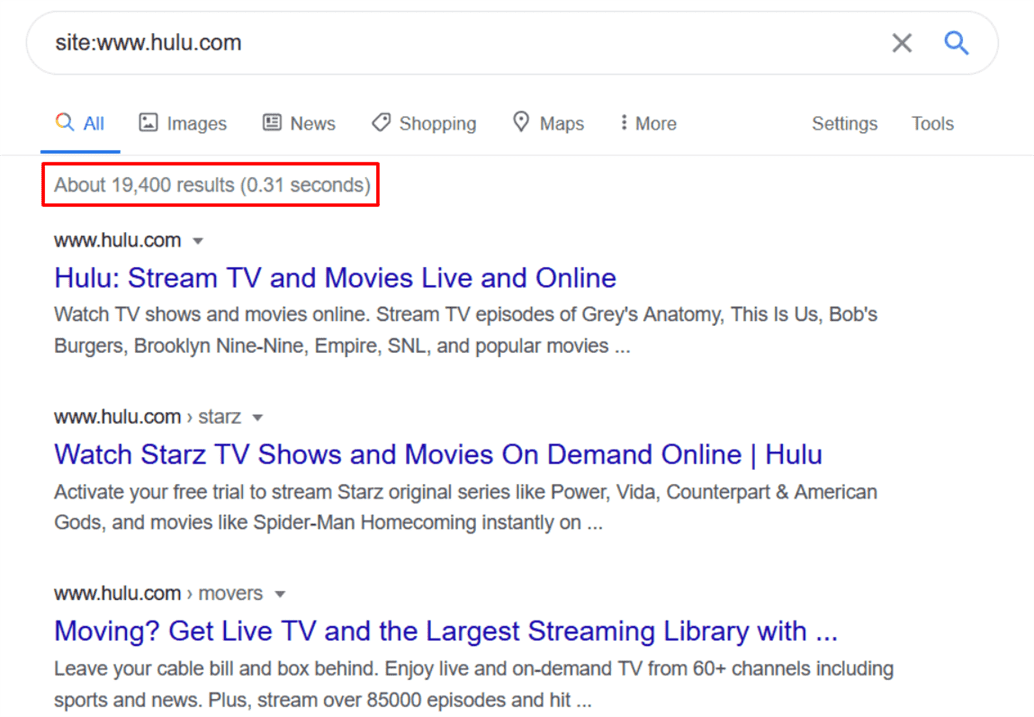
If the number of results is equal to or greater than the number of pages listed in the sitemap, you’re looking at a piping hot serving of index bloat supreme. As with drive-through nachos, more website indexation isn’t necessarily better website indexation.
If you want to end a site’s index bloat woes, the noindex tag is your new best friend. To use it, open any page’s HTML editor and add aL editor and add a quick line of code to the head section:
<meta name=”robots” content=”noindex”>
Alternatively, you can delete any pages that shouldn’t be indexed and provide no value to users. For example, a completely outdated or low-quality page should neither be indexed nor shown to visitors.
Contrast this with a “thank you for registering” page (for example), which shouldn’t be indexed, but should still be shown to users.
Maximize Page Speed
If you’ve ever waited an eternity (a.k.a. anything longer than ten seconds) for a site to load, you already know how vital page speed is to user experience.
What may be less obvious is how strongly page speed can also affect a site’s crawlability. While Googlebot can’t really get impatient, it does emulate human users by navigating sites using internal links.
The longer each page takes to load, the more a site’s crawl budget is depleted. In the worst cases, Google may stop crawling a site entirely and move on to a less sluggish destination.
To improve page speed and help search engine crawlers navigate sites with ease, use techniques such as:
- implementing image optimization;
- installing a WordPress caching plugin;
- reducing the number of server requests;
- reducing server response times;
- using asynchronous loading; and
- using a content delivery network (CDN).
Be More Mobile-Friendly
If you happened to make a bet ten years ago that mobile traffic would someday overtake desktop traffic, it’s time to cash in. (Lucky you!)
In July 2010, desktop devices accounted for just over 97 percent of internet traffic, with mobile devices producing just 2.86 percent. By July 2020, the tables had turned—50.88 percent of all internet traffic was from mobile devices, while 46.39 percent of traffic came from desktops.
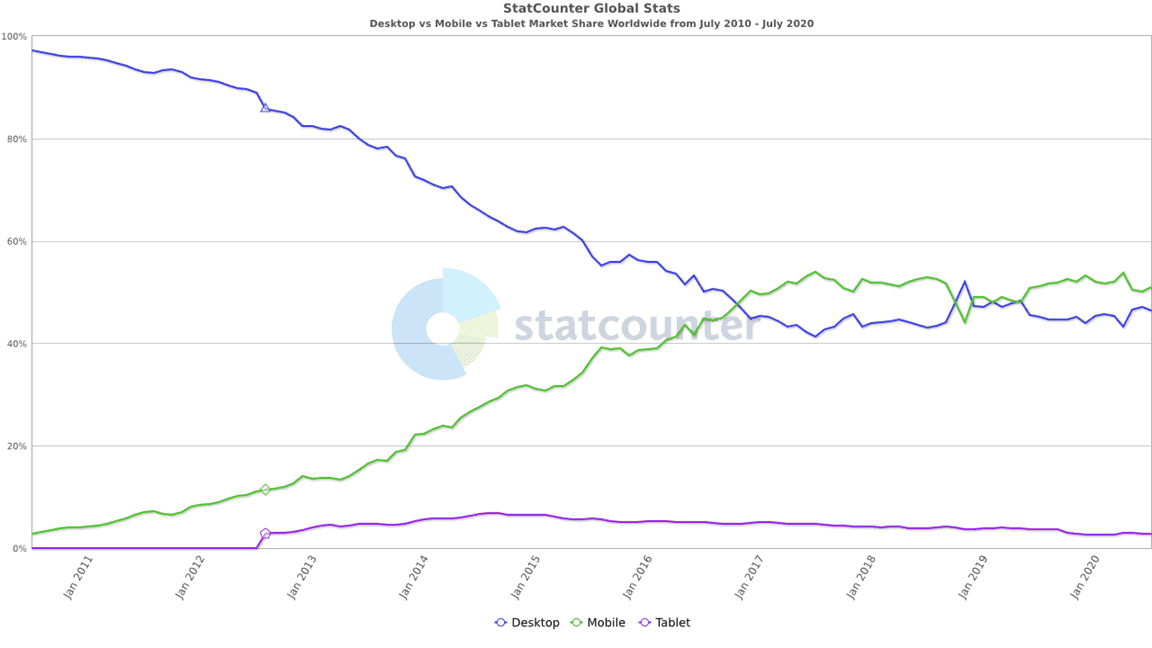
How does this affect crawlability? The answer lies in Google’s crawling methods: In an effort to adapt to the internet’s massive mobile traffic, Google has switched to mobile-first indexing for all sites.
This means Google primarily relies on a site’s mobile version to assign rankings. As a result, optimizing a site for mobile use isn’t just a good idea—it’s a necessity.
If you’re not sure exactly how to make a site as mobile-friendly as possible, start by following Google’s mobile-first indexing best practices:
- Ensure Google can access and render mobile pages’ content and resources.
- Confirm a site’s mobile pages contain the same content as its desktop pages.
- If you use structured data, include it on both desktop and mobile pages.
- Use the same metadata on a site’s mobile pages as its desktop pages.
- Follow the Coalition for Better Ads recommendations for mobile ad placement.
- Adhere to Google Image best practices.
- Adhere to Google’s video best practices.
- Take extra precautions to ensure separate mobile and desktop URLs function properly (you’d be better off not using separate URLs at all, though).
Once you’ve successfully optimized a site for mobile use, Google will have a much easier time crawling (and ranking!) its pages.
Fix Broken Pages
Crawl budget depletion can again rear its ugly head when a site has one or more broken pages.
Think of Googlebot like a person driving through a city: It wants to travel quickly and efficiently, but the more detours that crop up, the longer the trip takes. Broken pages are those detours, and too many can seriously impede site crawling.
Worse yet, broken pages can also prevent link equity from freely flowing between pages.
The first step to solving this pesky problem and making a site more crawlable is locating broken pages. You can do this quickly and automatically with the help of comprehensive paid tools like SEMrush’s Site Audit or Ahrefs’ Site Explorer, or you can use a simpler (but free) tool like Dead Link Checker.
For example, we scanned the New York Times food section landing page using Dead Link Checker and uncovered a total of three broken pages:
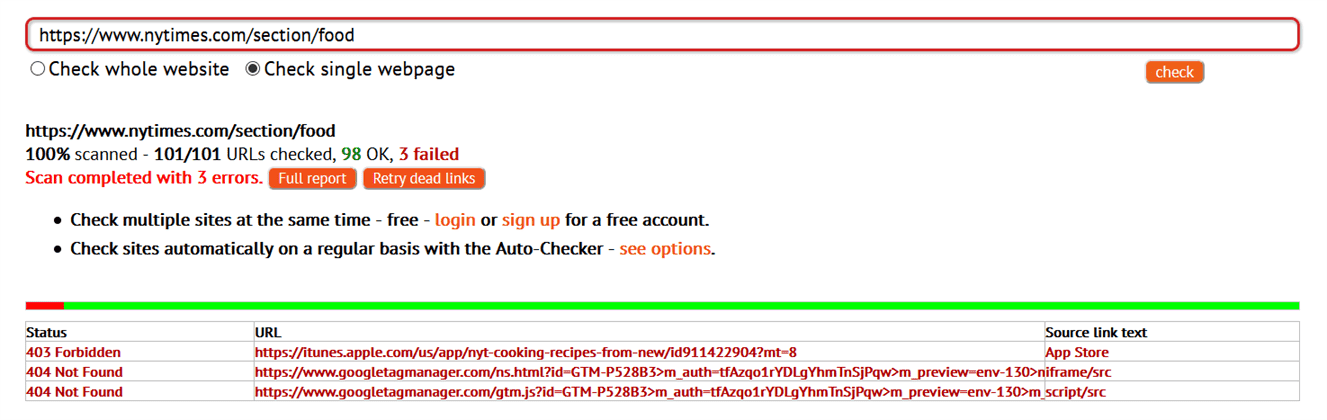
Once you’ve identified a site’s broken pages, determine how best to mend the breaks. Search engines displaying the incorrect link, or users linking to a nonexistent page is beyond your control. But you can absolutely control whether broken pages occur as a result of site migration or changing site structure.
For the broken pages you can control, use 301 redirects to keep both crawlers and human visitors moving in the right direction. For those you can’t, create a custom 404 page to provide the best possible user experience.
Organize Blog Pages
While Google’s algorithms are pretty darn good at identifying context and related content within a site, clear organization and labeling expedite the process considerably. This is especially true for blogs, where disorganized blog posts can quickly turn into a maze of hundreds or even thousands of uncategorized pages.
Keep the chaos under control by organizing a site’s blog posts using categories, tags, an archiving system or any combination of the three.
For instance, the food blog Cookie and Kate divides posts into broad categories such as breakfast, salad, soup and dinner:

From there, individual posts are organized even further with the help of category and ingredient tags like baked goods, dairy free, coconut oil and maple syrup:
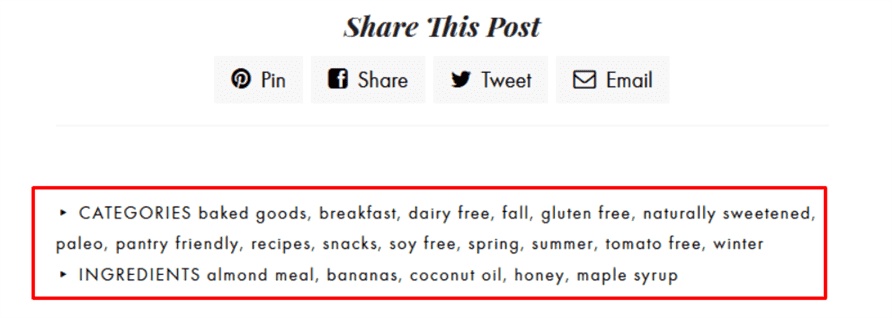
This type of stringent organization helps users find exactly what they’re looking for and boosts crawlability.
To start categorizing, tagging and archiving a blog yourself, first find out which types of organization the site’s CMS supports:
- WordPress supports categories, tags and archives.
- HubSpot supports tags and archives.
- Squarespace supports archives, categories and tags.
Take the time to categorize, tag or archive all the blog’s previous posts, and implement protocols to organize new posts, too.
Optimize JavaScript and CSS
To understand how different languages affect Google’s crawling behavior, think of websites as cars.
Markup languages such as HTML organize the internal parts working to keep gas and electricity flowing, programming languages such as JavaScript create the knobs and dials drivers actually interact with, and style sheet languages such as CSS determine those buttons’ design, colors and position.
HTML, JavaScript and CSS are all astoundingly prevalent across the web:
- More than 90 percent of websites use HTML.
- Over 95 percent use JavaScript.
- Over 95 percent use CSS.
Given their ubiquity, you’d be forgiven for thinking all three languages are equally crawlable in Google’s eyes. As with many aspects of SEO, though, things aren’t quite so simple, and both JavaScript and CSS can trip up Google’s crawlers if used improperly.
Follow Google’s recommendations to ensure its bots can crawl and index a site’s JavaScript and CSS files.
- Use the URL Inspection tool to see how Google views a page.
- Use the robots.txt Tester to make sure crawlers aren’t blocked from JavaScript and CSS content.
- Use the Mobile-Friendly Test to confirm a site’s JavaScript and CSS files can be properly rendered on mobile devices.
- Test both desktop and mobile URLs for crawlability (if you’re using separate ones for each).
As an added bonus, following these recommendations ensures image crawlability, too.
Tidy up the Sitemap
When exploring an unfamiliar city, one of the first things you’re likely to do is refer to a map—maybe even a paper one if you’re feeling particularly old school.
Googlebot is no different. As a crawler programmed by humans, it uses sitemaps to get around. A sitemap is a file outlining a site’s pages and media, and a well-organized one will show Google how a site’s parts relate to each other:
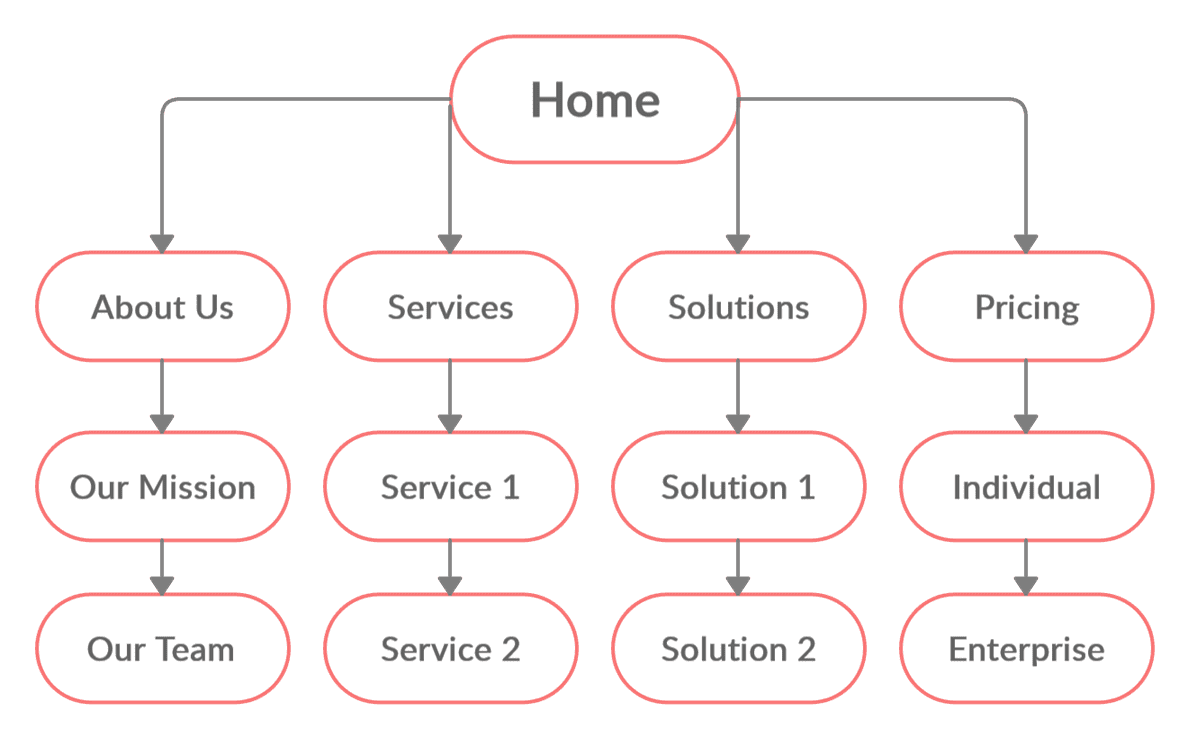
Google outlines three basic steps for building and submitting a sitemap:
- Decide which of a site’s pages Google should crawl, and use the canonical tag to identify the original version of any duplicate pages.
- Choose which format you want to use (options include XML, RSS and text).
- Ensure Google can access the sitemap by adding it to the robots.txt file or submitting it directly to Google.
Improve Crawlability and Rise through the Ranks
With thousands of tactics available to you as an SEO practitioner looking to boost sites’ rankings, it’s easy to get swept up in granular techniques and algorithm updates. But without a crawlable site, all your other SEO efforts will be moot.
Use the variety of crawlability-enhancing tools at your disposal to give Google and other search engines a clear path to your content. Banish bloat, make your site mobile friendly and keep your content clean and organized, and get set for colossal ranking performance that’ll help your sites rise above the competition.
Image credits
Screenshots by author / August 2020
StatCounter / July 2020
Illustration by author / August 2020




