Google recently unveiled its new SMITH algorithm, and it has massive implications for the future of content creation and search engine optimization.
If you want to be prepared for what Google has in store, learn how the SMITH algorithm works and whether it has what it takes to be the next BERT.
Google’s SMITH Algorithm at a Glance
The Siamese Multi-depth Transformer-based Hierarchical (SMITH) Encoder is a lot easier to understand than you’d think—no, really. In essence, it’s a neural network-based algorithm that’s designed to comprehend and identify relevance between long-form documents.
It does so by using a combination of machine learning techniques such as encoders, embeddings and transformers, as illustrated in Google’s research paper on the algorithm:
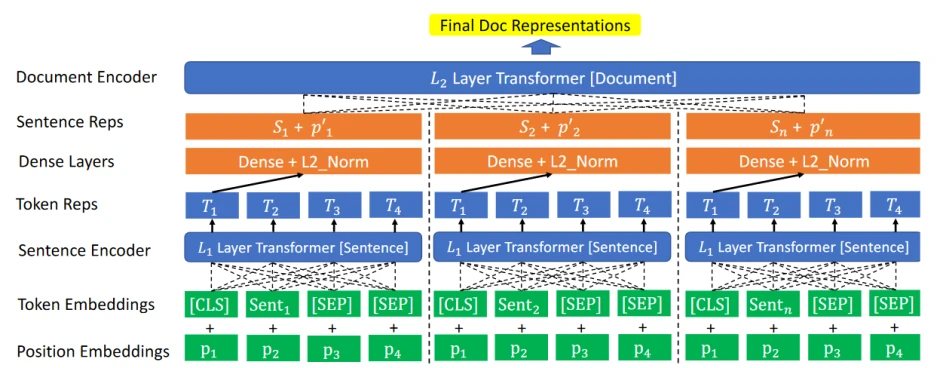
It may look complicated, but the end goal of all those processes is simple: To understand long pieces of text and ultimately determine whether they are relevant to each other or not.
Google researchers trained the algorithm in two phases. First, they pre-trained it with large quantities of unlabeled text and allowed it to learn unsupervised. Then, they fine-tuned it through the use of supervised document matching tasks.
SMITH vs. BERT
If you’ve been paying attention to Google’s algorithm updates over the last year, then you’re likely already familiar with BERT, or Bidirectional Encoder Representations from Transformers.
Just as with the SMITH algorithm, BERT is designed to comprehend and determine the relevance between pieces of text. It’s also trained in a similar method, first via unsupervised pre-training and next via supervised fine-tuning:
![]()
As Google proudly stated when introducing BERT, its GLUE (General Language Understanding Evaluation) score reached 80.5 percent, an impressive 7.7 percent improvement over previous models.
BERT was clearly a winner, and Google reacted by quickly implementing it. As it announced at its Search On 2020 event, BERT is now used in almost every English search query and is helping make Google’s search results more accurate than ever.
Given BERT’s success, it came as a surprise to see a fresh research paper from Google detailing how SMITH not only met but exceeded BERT’s ability to understand and match long-form documents specifically.
Why? As Google explained in its paper, while models like BERT are highly accurate, they “are still limited to short text like a few sentences or one paragraph.”
Will SMITH Replace BERT?
On the surface, it might sound like the SMITH algorithm is poised to replace BERT. It’s important to remember, though, that SMITH only out-performs BERT when it comes to long-form documents. At the moment, it’s safe to assume that BERT still reigns supreme in terms of short pieces of text.
So, it might make more sense for Google to use SMITH in conjunction with BERT. With both working together, the search engine would be able to understand and match both long- and short-form content.
But this is all speculation until SMITH is actually implemented, and as Google Search Liaison Danny Sullivan clearly stated in a tweet, SMITH is not live:
We publish a lot of papers about things not used in Search. I won’t be making a habit of confirming each one someone might speculate about because it’s time consuming & more important, we have tended to proactively talk about this stuff already. That said. No. We did not.
— Danny Sullivan (@dannysullivan) January 13, 2021
Live or Not, SMITH Is a Big Deal
Even if SMITH never goes live, it’s useful for SEO practitioners to know that Google is making strides its ability to effectively understand and index long-form text and will soon be able to accurately match it with users’ queries.
For you, this means it’s time to focus on high-quality content creation and entity optimization. This way, you’ll be able to ensure that your long-form content is ready to top the SERPs whenever SMITH (or an algorithm like it) does go live.
Image credits
Google Research / October 2020
Google Research / October 2018





