The world of SEO is littered with references to Google’s algorithm updates. But if you don’t know how their algorithms actually work, then you won’t have much use for those up-to-the-minute updates on their inner workings.
Here, we’ll explain exactly how Google’s algorithms work so you can start optimizing for them more effectively than ever before.
- The Early Days of Google’s Algorithms
- Crawling and Indexing the Web
- Deciphering User Queries
- Determining Relevance
- Evaluating Page Speed and Quality
- Analyzing Page Experience
The Early Days of Google’s Algorithms
In April 1998, Stanford students Larry Page and Sergey Brin published a research paper titled The Anatomy of a Large-Scale Hypertextual Web Search Engine. It introduced Google, a search engine “designed to crawl and index the web efficiently and produce much more satisfying search results than existing systems.”
Although Google’s algorithm has since advanced by leaps and bounds, its 1998 iteration is still familiar. As Page and Brin explained, the first Google algorithm calculated rank based on a number of factors including:
- each page’s incoming and outgoing links;
- each link’s anchor text; and
- the various keywords found on a given page.
It may sound simple, but keep in mind that in the 1990s most search engines functioned only by matching keywords to queries. This generated less-than-satisfactory search results, and Google’s new, more nuanced algorithm was a revelation.
With its invention, users saw the quality of their search results skyrocket and a new standard for search engines was born.
As you probably already know, Google saw incredible success as a result—between 2002 and 2020, the company’s annual revenue increased by close to 200 billion dollars:
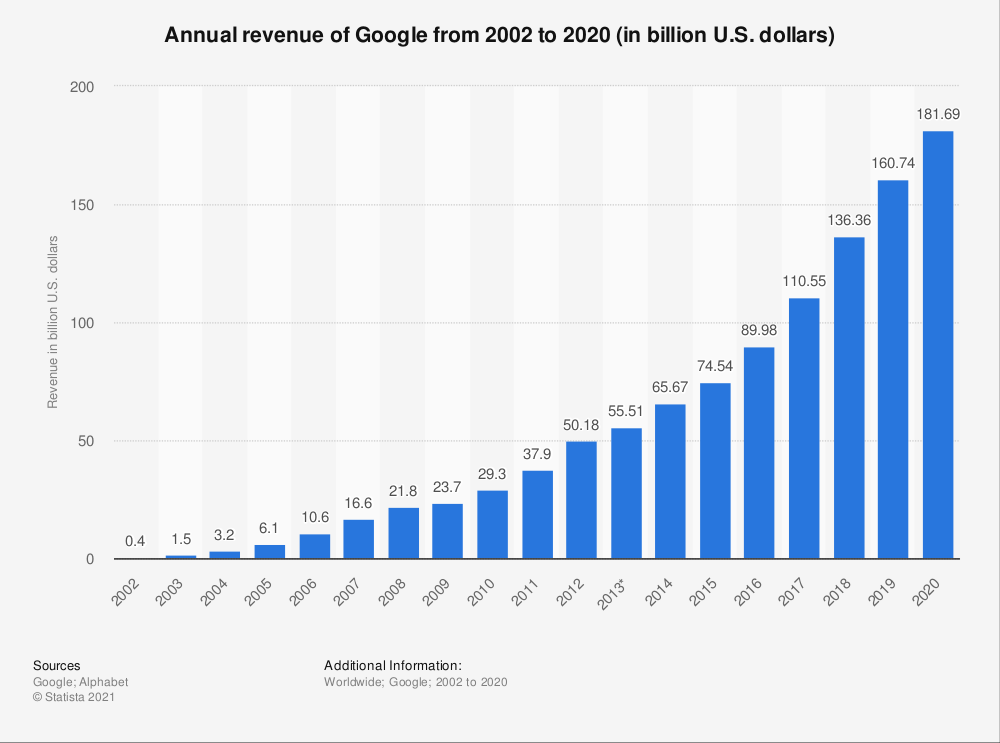
But how do Google’s algorithms work today after decades of development? Keep reading to find out.
Crawling and Indexing the Web
Just like Google’s original algorithm, its modern iterations start by crawling and indexing as many web pages as possible.
Crawling simply refers to the process in which Google’s web crawler (colloquially known as Googlebot) visits and looks at pages, all while accompanied by an endearing arachnid sidekick, of course.

When Googlebot visits a page, it will also follow any links the page contains. This makes it easy to see why crawlers are sometimes called spiders; they move from page to page as if climbing from one strand of a spider web to another.
This behavior is designed to imitate that of real, human users who navigate sites by clicking on links. It serves to demonstrate the importance of logical site organization and a recently updated sitemap—with their help, your site’s crawlability can drastically improve.
After crawling a page, Googlebot then sends the information it’s gathered to Google’s index where it’s filed away for future retrieval. This process is known as website indexation.
Google’s Search index stores information about hundreds of billions of web pages, and is more than 100 million gigabytes in size (that’s over 100 petabytes). When a user makes a search query, all the results Google delivers are pulled from its index.
So how does Google determine which results are worth delivering and which aren’t? That’s where the magic of its search algorithms come in.
Deciphering User Queries
The first step toward giving users the high-quality search results they desire is to accurately decipher what their search queries really mean.
This is done not only by matching keywords in queries to keywords in pages, but also by interpreting spelling mistakes and identifying synonyms. As Google points out, its synonym system helps discern when multiple words can satisfy the same query:
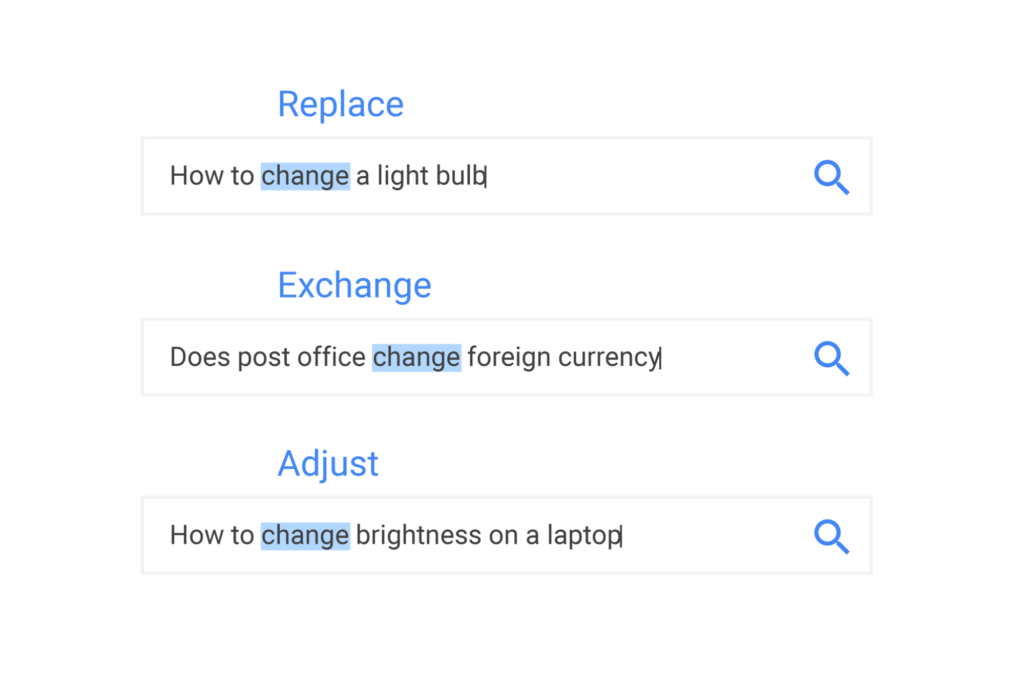
Google has also invested a great deal of time and money in teaching its machine learning systems how to understand the meaning of and context behind queries. Take for instance its BERT and SMITH models, both of which are carefully designed to accurately interpret phrases.
As Google explained on its blog, BERT makes it possible to return a search result that’s highly relevant rather than generic:
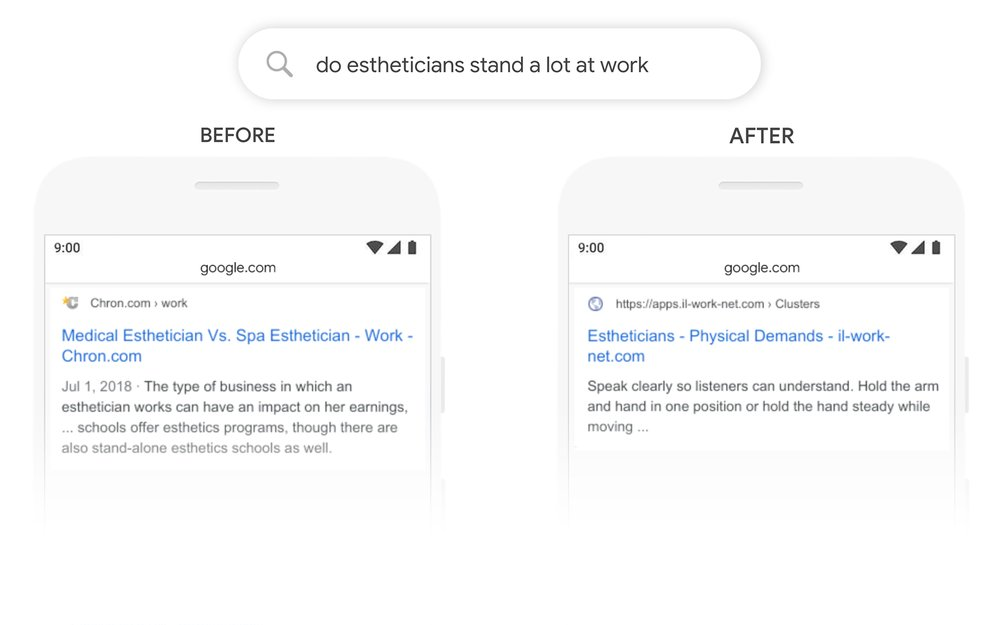
And behind the scenes, Google’s engineers are constantly working to build even more advanced machine learning models that come as close as possible to a human level of language comprehension.
Determining Relevance
Once Google’s algorithms have identified what a user is looking for, their next task is to determine which web pages are relevant and which are not.
Google can accomplish this by analyzing hundreds of different factors, the most basic of which being keyword presence. It does so with the help of deep learning models like SMITH and BERT, and also uses its proprietary Knowledge Graph to tell which pages will best answer a given query.
Put simply, the Knowledge Graph is a collection of billions of facts about people, places and things—in other words, it’s the ultimate encyclopedia. It knows things like the exact date of Franklin D. Roosevelt’s birthday, the length of the Great Wall of China and the height of a typical giraffe:
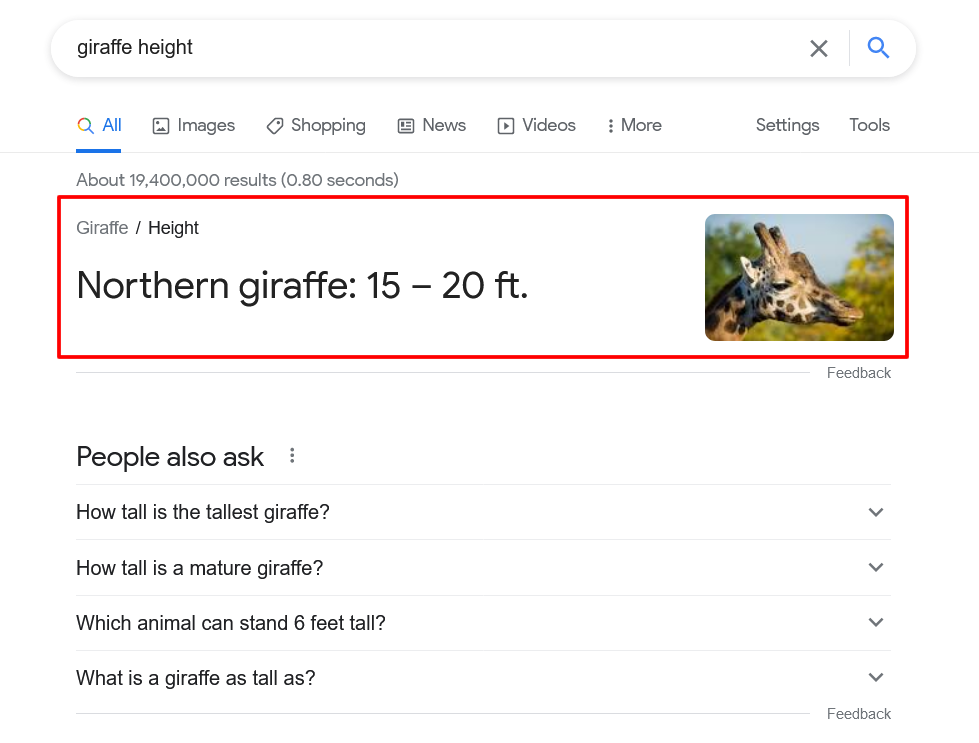
To ensure every query is answered as correctly as possible, the Knowledge Graph pulls from a variety of sources. Sometimes that means governments, schools and scientific institutions, but it can also mean websites like yours.
If your website is used to answer a user’s factual query, the relevant content will be displayed in a knowledge panel. These are “information boxes that appear on Google when you search for entities (people, places, organizations, things) that are in the Knowledge Graph.”
What’s more, if you “are the subject of or official representative of an entity depicted in a knowledge panel, you can claim this panel and suggest changes.” For example, if you’re the webmaster of a museum’s website, you can claim and update that museum’s knowledge panel to ensure complete accuracy.
More broadly, you can help Google’s algorithms recognize when your site’s pages are relevant to users’ queries by keeping each page firmly on-topic and implementing good entity optimization practices.
Evaluating Page Speed and Quality
Part of the reason that Google’s algorithms are so advanced is that they’re tuned to evaluate numerous factors affecting the user experience. These include things like:
- page speed;
- mobile-friendliness;
- content quality; and
- expertise, authoritativeness and trustworthiness (E-A-T).
(Please note that E-A-T is a concept, not a ranking factor. Google’s Danny Sullivan and Gary Illyes have both explained that a group of combined factors, such as links (which count as authority, per Gary) could all contribute to higher site quality and thus could potentially count towards the concept of E-A-T. Per Google, on multiple occasions, E-A-T does not currently exist in the algorithm as an individual E-A-T score or algorithmic attribute.)
While there are hundreds of ways you can tweak your website in order to improve those factors, some of the most fundamental include:
- using a WordPress caching plugin;
- removing unnecessary or outdated WordPress plugins;
- prioritizing image optimization;
- adopting responsive web design;
- eliminating long walls of text;
- striving for the highest-quality content possible;
- tailoring your content to suit your target audience; and
- ensuring accuracy and transparency across your site.
And to help keep tabs on your progress, you can use tools like Google’s Mobile-Friendly Test and PageSpeed Insights.
Analyzing Page Experience
Google’s page experience update was originally scheduled for May 2021, but first started rolling out in June. As its name suggests, it’s centered around the experience users have on any given page.
This includes things we’ve already discussed here, such as page speed and mobile-friendliness. But is also includes factors called Core Web Vitals, a trio of signals called Largest Contentful Paint (LCP), First Input Delay (FID) and Cumulative Layout Shift (CLS).
LCP measures loading speed, FID measures interactivity and CLS measures visual stability:
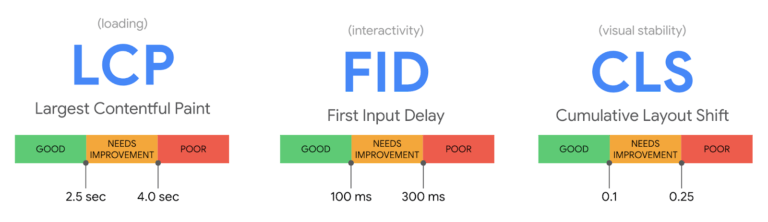
With the page experience update now live, it’s crucial for SEO practitioners to consider those three signals when optimizing their sites’ pages.
The update includes more than Core Web Vitals, though—it also considers mobile-friendliness, safe browsing, Hypertext Transfer Protocol Secure (HTTPS) and a lack of intrusive interstitials:
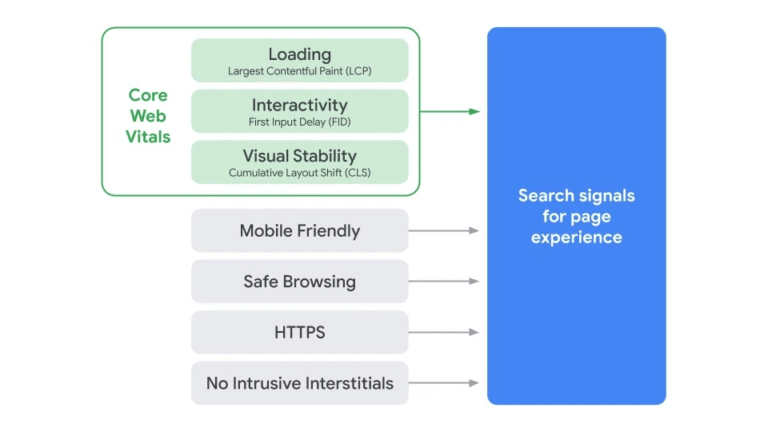
So to truly optimize your site for the page experience update, you need to account for those signals too.
Reverse Engineer Google’s Algorithms to Move Your SEO Forward
It makes sense that the most skilled SEO pros are often those with a deep understanding of how search engines work. After all, you need to understand how a car works in order to be a good mechanic.
And since Google is by far the largest and most powerful search engine in the world, you can become a better SEO practitioner yourself by learning how its algorithms work and reverse engineering them to your advantage.
Image credits
CNN / September 2015
Statista / February 2021
Google / Accessed June 2021
Screenshots by author / June 2021







